WebScraper是Mac下一款网站数据采集工具,通过它使用将数据导出为JSON或CSV的极简主义应用,快速提取与特定网页相关的信息,包括文本内容。
WebScraper使您可以轻松地从在线资源中快速提取内容。您可以完全控制将导出到CSV或JSON文件的数据。
使用多个线程快速扫描任何网站
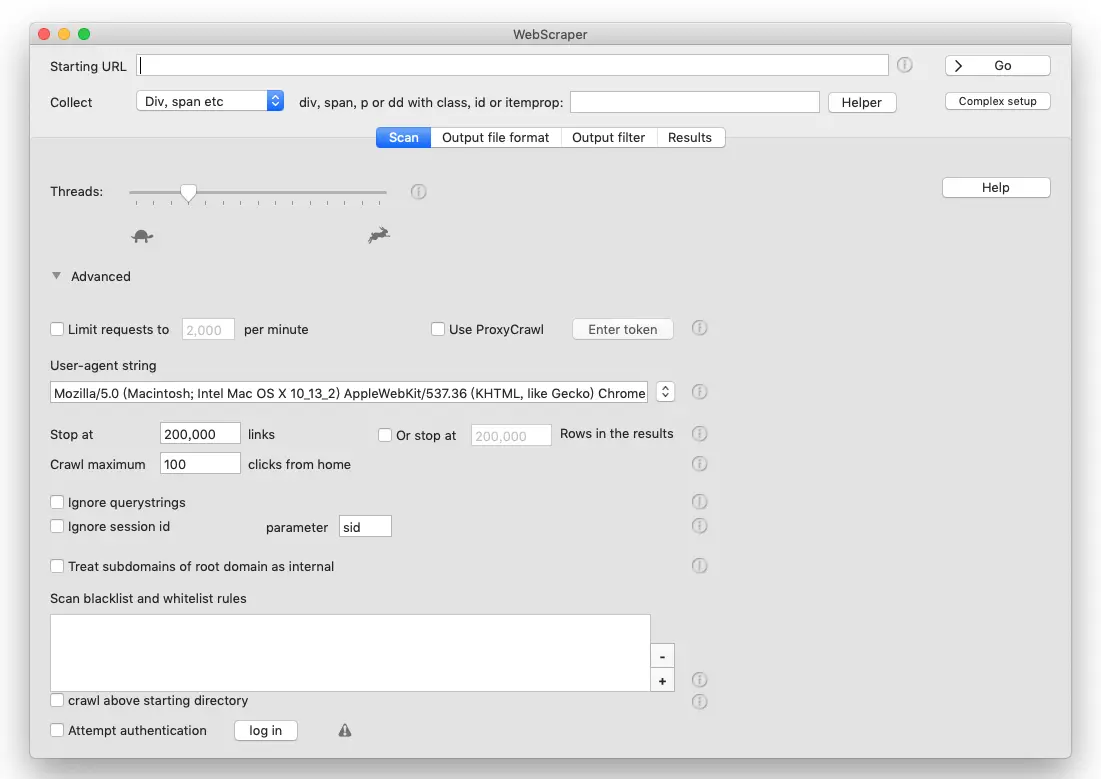
在WebScraper主窗口中,您必须指定要扫描的网页的URL地址,以及用于完成该过程的线程数。您可以借助简单的滑块调整后一个参数。
为避免任何不必要的扫描,您可以选择仅抓取单个页面,然后只需单击鼠标即可启动该过程。在“实时视图”窗口中,您可以看到每个链接返回的状态消息,这在处理调试任务时可能非常有用。
提取各种类型的信息并将数据导出为CSV或JSON
在WebScraper输出面板中,您可以选择希望实用程序从网页中提取的信息类型:URL,标题,描述,与不同类或ID关联的内容,标题,页面内容各种格式(纯文本,HTML或Markdown)和上次修改日期。
您还可以选择输出文件格式(CSV或JSON),决定合并空格,并在文件超过特定大小时设置警报。如果您选择CSV格式,则可以选择何时使用列周围的引号,采用什么而不是引号或行分隔符类型。
最后但同样重要的是,WebScraper还允许您更改用户代理,设置链接数量限制和来自主页的点击,可以忽略查询字符串,并可以将根域的子域视为内部页面。
无需过多的用户交互即可轻松抓取在线资源中的信息
WebScraper为您提供了快速扫描网站并将其内容以及其他附加内容输出到CSV的JSON文件的可能性。每当您想要离线访问数据时,该工具都很棒,而无需存储整个页面。
主要特点:
- 快速轻松地扫描网站
- 大量提取选项,包括各种元数据,内容如(如文本,html或markdown)HTML元素与某些类/标识符,正则表达式
- 轻松导出:选择所需的列
- csv或JSON输出为
- 生成单个文本文件的新选项(用于存档文本内容,折扣或纯文本)
- 很多选项/设置
- 设置多个跟踪并限制输出文件的大小
兼容性OS X 10.8或更高版本的64位
网站:http://peacockmedia.co.uk/


文章评论 (0)